随着《數據安(ān)全法》《個人信息保護法》《網絡數據安(ān)全管理(lǐ)條例》等一系列法律法規相繼實施,在政策法規層面極大地促進了數據安(ān)全分(fēn)類分(fēn)級市場的發展。
與此同時人工(gōng)智能(néng)技(jì )術、行業大模型在數據分(fēn)類分(fēn)級領域的應用(yòng),推動了數據分(fēn)類分(fēn)級産(chǎn)品技(jì )術和應用(yòng)的快速叠代。
數據安(ān)全分(fēn)類分(fēn)級産(chǎn)品已成為(wèi)政企單位數據安(ān)全治理(lǐ)的重要工(gōng)具(jù),是開展數據安(ān)全保護建設的基礎。
本文(wén)将從用(yòng)戶視角出發,結合行業實際及美創科(kē)技(jì )數據安(ān)全分(fēn)類分(fēn)級平台優勢,深度分(fēn)析數據安(ān)全分(fēn)類分(fēn)級産(chǎn)品選型時需重點關注的五個層面。
合規性驅動是政企單位開展數據安(ān)全建設的主要因素之一,數據安(ān)全分(fēn)類分(fēn)級工(gōng)作(zuò)也是如此,滿足國(guó)家、行業監管要求是用(yòng)戶關注的重點之一。
GB/T 43697-2024《數據安(ān)全技(jì )術 數據分(fēn)類分(fēn)級規則》根據相關法律法規規定,給出了分(fēn)類分(fēn)級通用(yòng)規則,用(yòng)于指導各行業、各地區(qū)、各部門和數據處理(lǐ)者開展數據分(fēn)類分(fēn)級工(gōng)作(zuò)。
在實際落地數據分(fēn)類分(fēn)級工(gōng)作(zuò)中(zhōng),常面臨用(yòng)戶所屬的地區(qū)、行業沒有(yǒu)分(fēn)類分(fēn)級的标準和規範的情況,如此一來需要從制定數據安(ān)全分(fēn)類分(fēn)級标準規範做起。美創科(kē)技(jì )會充分(fēn)評估用(yòng)戶業務(wù)數據情況,通過“咨詢服務(wù)+數據安(ān)全分(fēn)類分(fēn)級平台”的方式解決。
如用(yòng)戶所在行業具(jù)備數據分(fēn)類分(fēn)級标準,美創科(kē)技(jì )會将其轉換成統一的分(fēn)類分(fēn)級大綱格式,并導入數據安(ān)全分(fēn)類分(fēn)級平台,形成可(kě)落地的分(fēn)類分(fēn)級方案。
整體(tǐ)而言,不同行業的差異性主要體(tǐ)現在分(fēn)類的層級不同、對安(ān)全級别的命名(míng)差異。美創數據安(ān)全分(fēn)類分(fēn)級平台通過不限制分(fēn)類層次、自定義安(ān)全級别名(míng)稱、動态分(fēn)級等功能(néng)對不同行業分(fēn)類分(fēn)級差異性進行兼容,最大程度滿足各行業的分(fēn)類分(fēn)級訴求。
數據安(ān)全分(fēn)類分(fēn)級産(chǎn)品中(zhōng),敏感數據識别準确率是關鍵。常規産(chǎn)品實現中(zhōng),常采用(yòng)正則、關鍵字、數據字典等基于字段名(míng)、字段備注、字段内容等滿足基本語義識别。除此之外,美創科(kē)技(jì )還将自然語言處理(lǐ)(NLP)、大語言模型(LLM)、詞嵌入(WordEmbeddings)等多(duō)種機器學(xué)習算法模型内置為(wèi)平台智能(néng)引擎,構建語義知識庫,為(wèi)LLM提供豐富的上下文(wén)信息,确保語義識别和分(fēn)類分(fēn)級推薦的精(jīng)準性,在保證算力要求下,✅準确率可(kě)達85%-95%。
在數據顆粒度和标注能(néng)力方面,美創數據分(fēn)類分(fēn)級平台對結構化數據可(kě)标注到每個字段,對長(cháng)文(wén)本中(zhōng)的内容進行敏感數據識别,按詞分(fēn)割打标,标注到數據所在的具(jù)體(tǐ)位置。最後根據字段的标注,按照規則對表、文(wén)件等數據集進行數據集的分(fēn)類分(fēn)級标注。
在分(fēn)類分(fēn)級結果确認之後,美創利用(yòng)特征工(gōng)程技(jì )術,對結果進行深入建模和學(xué)習,建立一個動态更新(xīn)的分(fēn)類分(fēn)級模型,從而實現對新(xīn)增業務(wù)字段的自動智能(néng)化分(fēn)類分(fēn)級,日積月累,不斷叠代。
智能(néng)化和自動化水平直接關乎數據安(ān)全分(fēn)類分(fēn)級産(chǎn)品的交付效率和成本,也因此成為(wèi)用(yòng)戶選型的又(yòu)一重要指标。回顧數據安(ān)全分(fēn)類分(fēn)級産(chǎn)品剛推出的前幾年,曾因為(wèi)海量數據、較高的人工(gōng)成本(人工(gōng)咨詢、人工(gōng)标注、人工(gōng)校正分(fēn)類分(fēn)級結果)導緻整體(tǐ)分(fēn)類分(fēn)級項目成本居高不下,産(chǎn)品也很(hěn)難标準化和産(chǎn)業化。
美創科(kē)技(jì )産(chǎn)品專家認為(wèi),分(fēn)類分(fēn)級的自動化主要體(tǐ)現在敏感數據的自動發現、增量數據的自動發現、自動化的分(fēn)類分(fēn)級。其中(zhōng)增量數據的自動發現可(kě)以通過元數據變更檢測,自動提示用(yòng)戶,分(fēn)類分(fēn)級作(zuò)業也支持單獨對新(xīn)增字段進行分(fēn)類分(fēn)級,推薦新(xīn)增字段的分(fēn)類和分(fēn)級。分(fēn)類分(fēn)級智能(néng)化的第一步,是對數據字段的含義進行準确識别,詳細實現見上面闡述。
其次在數據分(fēn)類分(fēn)級産(chǎn)品的流程上,通過高效的配置,可(kě)提升産(chǎn)品的效率,比如可(kě)先對表進行分(fēn)類分(fēn)級,表内字段可(kě)批量設置為(wèi)同表的分(fēn)類分(fēn)級結果;人工(gōng)已确認的分(fēn)類分(fēn)級結果,重新(xīn)跑作(zuò)業時,分(fēn)類分(fēn)級結果不會被覆蓋;人工(gōng)稽核分(fēn)類分(fēn)級結果時可(kě)批量同時調整多(duō)個字段等等。
某大數據局數據安(ān)全分(fēn)類分(fēn)級實踐
在某大數據局實現分(fēn)類分(fēn)級與資産(chǎn)編目系統對接中(zhōng),分(fēn)類分(fēn)級系統根據表名(míng)、表注釋、列名(míng)、列注釋利用(yòng)AI語義識别能(néng)力對字段進行分(fēn)類分(fēn)級,并通過接口返回分(fēn)類分(fēn)級結果。人工(gōng)确認或調整确認後可(kě)反哺到系統進行建模分(fēn)析,實現數據資産(chǎn)在注冊時同步分(fēn)類分(fēn)級的效果。大大減少後期二次資産(chǎn)盤點、與業務(wù)部門确認溝通的成本。
在數據安(ān)全分(fēn)類分(fēn)級産(chǎn)品選型過程中(zhōng),性能(néng)意味着處理(lǐ)速度,穩定性更是基礎。
美創數據分(fēn)類分(fēn)級平台對于整體(tǐ)性能(néng)的提升采用(yòng)合理(lǐ)的數據庫設計、索引優化、緩存數據、使用(yòng)異步處理(lǐ)等方法,以提升後台處理(lǐ)速度,保證平台快速響應用(yòng)戶需求。
穩定性保障方面,配置監控系統,實時監測各項指标,如服務(wù)器負載、内存使用(yòng)、網絡流量等;使用(yòng)負載均衡技(jì )術來平衡服務(wù)器負載,保證系統穩定運行,同時可(kě)以根據需求進行水平擴展,以應對高并發情況;系統設計上考慮容錯機制,升級與修複時會對數據進行備份,并建立完善的數據恢複機制,以防止數據丢失或損壞。
分(fēn)類分(fēn)級結果應用(yòng)與系統兼容性
數據安(ān)全治理(lǐ)需要基于分(fēn)類分(fēn)級結果實施精(jīng)細化安(ān)全防護,這要求數據安(ān)全分(fēn)類分(fēn)級産(chǎn)品具(jù)備開放接口,以實現安(ān)全設備聯動。美創數據安(ān)全分(fēn)類分(fēn)級平台通過數據分(fēn)類分(fēn)級輸出敏感、核心、重要數據,再聯動安(ān)全産(chǎn)品可(kě)實現敏感數據在生産(chǎn)運維、測試、取數等場景下分(fēn)類管理(lǐ)、分(fēn)級保護、權限适當,非敏感數據實現最大程度開放共享。
此外,美創數據安(ān)全分(fēn)類分(fēn)級産(chǎn)品提供強大的數據集管理(lǐ)能(néng)力,提供重要數據資産(chǎn)目錄,滿足各種場景下的取數、用(yòng)數和數據上報需求。
對于系統兼容和擴展,需要充分(fēn)考慮操作(zuò)系統、數據庫、中(zhōng)間件國(guó)産(chǎn)化的适配和改造,同時對國(guó)産(chǎn)數據庫、大數據平台、各類關系型數據庫、各類文(wén)件資産(chǎn)的分(fēn)類分(fēn)級快速兼容和支持。
美創數據安(ān)全分(fēn)類分(fēn)級平台
美創數據安(ān)全分(fēn)類分(fēn)級平台,動态發現并智能(néng)識别涉及國(guó)家、個人和組織安(ān)全的核心、重要和一般數據,依照對應的标準對數據進行分(fēn)類和分(fēn)級,形成符合标準的可(kě)視化數據目錄清單,以支撐不同場景下的安(ān)全合規和精(jīng)細化管控訴求。
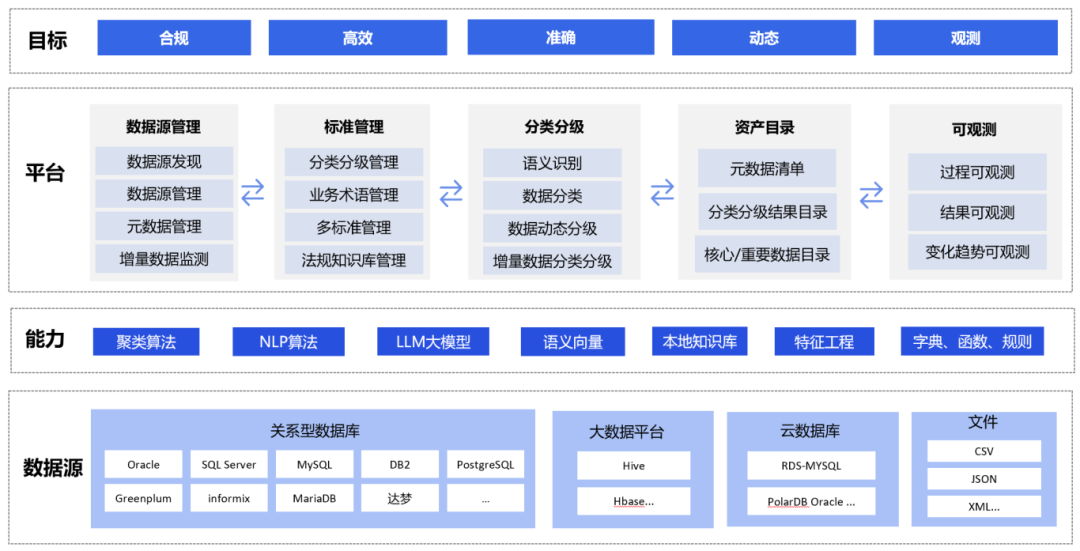
[美創數據安(ān)全分(fēn)類分(fēn)級平台架構圖]
平台支持接入多(duō)種類型的數據源,包括關系型數據庫、大數據平台、雲數據庫、文(wén)件等,能(néng)夠對多(duō)種類型的數據源進行元數據掃描和樣本數據采集,通過多(duō)種智能(néng)算法和大模型能(néng)力實現對數據語義的識别,并基于分(fēn)類分(fēn)級标準和數據規模對數據進行分(fēn)類和分(fēn)級打标,形成符合行業标準的可(kě)視、可(kě)知、有(yǒu)序、多(duō)樣的資産(chǎn)目錄清單,支持通過清單導出、接口推送、訂閱等方式實現外發。為(wèi)最大程度的安(ān)全共享和精(jīng)細化安(ān)全防護提供基礎依據。
目前,美創數據安(ān)全分(fēn)類分(fēn)級平台已在大數據局、人社、高校、能(néng)源、金融、醫(yī)療、企業、教育等領域廣泛實踐。







 浙公(gōng)網安(ān)備 33010502006954号
浙公(gōng)網安(ān)備 33010502006954号